Media Summary: We present a self-supervised framework to infer both 3D human pose and shape from unlabeled images without accessing any ... Authors: Shruti Vyas, Yogesh Rawat, Mubarak Shah Published: Authors: Kara Marie Schatz, Erik Quintanilla, Shruti Vyas, Yogesh S Rawat Published:
10min Video For Eccv Oral - Detailed Analysis & Overview
We present a self-supervised framework to infer both 3D human pose and shape from unlabeled images without accessing any ... Authors: Shruti Vyas, Yogesh Rawat, Mubarak Shah Published: Authors: Kara Marie Schatz, Erik Quintanilla, Shruti Vyas, Yogesh S Rawat Published: We introduce Class-Incremental Domain Adaptation (CIDA) that enables the recognition of both shared and novel target ... Hyeonwoo Kim, Sookwan Han, Patrick Kwon, Hanbyul Joo. A class-agnostic object pose transformation network (OPT-Net) can transform an image along 3D yaw and pitch axes to ...
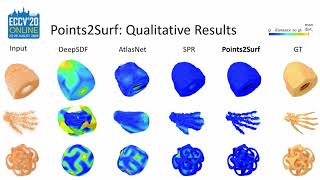
Chen Wang, Wenshan Wang, Yuheng Qiu, Yafei Hu, and Sebastian Scherer, Visual Memorability for Robotic Interestingness via ... Our new surface reconstruction method uses a fine local prior together with a coarse global one. With this, we can reconstruct ...

![[ECCV 2020 Oral] Appearance Consensus Driven Self-Supervised Human Mesh Recovery (10 min talk)](https://i.ytimg.com/vi/IBHc6y0x2y0/mqdefault.jpg)
![[ECCV-2020] Multi-view Action Recognition using Cross-view Video Prediction (10 Min summary)](https://i.ytimg.com/vi/jh_FqTt_fuw/mqdefault.jpg)
![[ECCV-2020] A Recurrent Transformer Network for Novel View Action Synthesis (10 Min summary)](https://i.ytimg.com/vi/CFQsjxaf5Nk/mqdefault.jpg)
![[ECCV 2020] Class-Incremental Domain Adaptation (10 min talk)](https://i.ytimg.com/vi/V5hRI1B5Efw/mqdefault.jpg)




![[ECCV 2020 Oral] Appearance Consensus Driven Self-Supervised Human Mesh Recovery (2 min talk)](https://i.ytimg.com/vi/LF6iyEMMcG8/mqdefault.jpg)
![[ECCV 2020 10min] Unselfie: Translating Selfies to Neutral-pose Portraits in the Wild](https://i.ytimg.com/vi/b2IdzUe2hxI/mqdefault.jpg)
![[1st Place] ECCV 2020: VI Priors Action Recognition Challenge: "Kallis" UCF-CRCV submission](https://i.ytimg.com/vi/_UM8k4in6J4/mqdefault.jpg)
