Media Summary: To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ... Build better full-stack authentication and user management with Clerk: -- We just launched the ... Breaking down how Large Language Models work, visualizing how data flows through. Instead of sponsored ad reads, these ...
Attention In Transformers Step By - Detailed Analysis & Overview
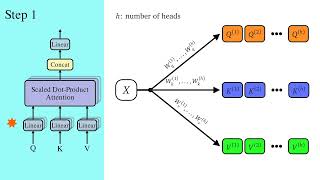
To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ... Build better full-stack authentication and user management with Clerk: -- We just launched the ... Breaking down how Large Language Models work, visualizing how data flows through. Instead of sponsored ad reads, these ... Why are the terms Query, Key, and Value used in self- In this video, I will first give a recap of Scaled Dot-Product A complete explanation of all the layers of a