Media Summary: For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ... Become AI Researcher (Skool) - In this tutorial you'll learn In this talk, Jeff Niu from OpenAI explores how he brought
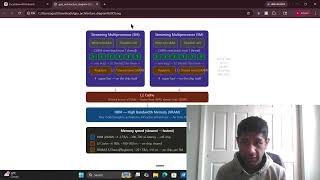
Coding A Triton Kernel For - Detailed Analysis & Overview
For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ... Become AI Researcher (Skool) - In this tutorial you'll learn In this talk, Jeff Niu from OpenAI explores how he brought Matrix Multiplication is the heart of every Transformer model. If it's slow, your model is slow. In this episode of Bielik Anatomy, we ... Byron Hsu presents LinkedIn's open-source collection of In our quest to build a deep learning framework, we have hit a roadblock! Training is too slow and needs too much memory for ...
I loaded a 1.5B parameter LLM on a GTX 1650Ti, wrote a 30-line For more information about Stanford's online Artificial Intelligence programs, visit: To learn more about ... Lean how to program with Nvidia CUDA and leverage GPUs for high-performance computing and deep learning.