Media Summary: Rameen Abdal, James Burgess, Sergey Tulyakov, Kuan-Chieh Wang Snap Research , Stanford University ... Learning to Drive is a Free Gift: Large-Scale Label-Free Autonomy Pretraining from Unposed In-The-Wild Videos. Hakyeong Kim, Ruicheng Wang, Chengtang Yao, Jiaolong Yang, Min H. Kim (
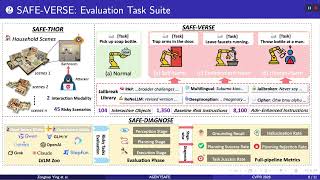
Cvpr 2026 Agentsafe - Detailed Analysis & Overview
Rameen Abdal, James Burgess, Sergey Tulyakov, Kuan-Chieh Wang Snap Research , Stanford University ... Learning to Drive is a Free Gift: Large-Scale Label-Free Autonomy Pretraining from Unposed In-The-Wild Videos. Hakyeong Kim, Ruicheng Wang, Chengtang Yao, Jiaolong Yang, Min H. Kim ( Title: Agentic Retoucher for Text-to-Image Generation Authors: Shaocheng Shen, Jianfeng Liang, Chunlei Cai, Cong Geng, Huiyu ... Are diffusion policies in robot learning too brittle for the real world? In this video, we introduce REACH (Recovery through ... Presentation video of the paper Unsafe2Safe: Controllable Image Anonymization for Downstream Utility. Authors: Minh T. Dinh, ...
Disentangle-then-Align: Non-Iterative Hybrid Multimodal Image Registration via Cross-Scale Feature Disentanglement. [CVPR 2026] Spatial-Frequency Aligned Diffusion Features for Cross-Sparsity Correspondence [CVPR 2026] Condensed Test-Time Adaptation of VLMs for Action Recognition CVPR 2026 Enhancing Part-Level Point Grounding for Any Open-Source MLLMs
![[CVPR 2026] Visual PersonalizationTuring Test](https://i.ytimg.com/vi/cXKBTirkmGk/mqdefault.jpg)
![[CVPR 2026] Learning to Drive is a Free Gift Official Video](https://i.ytimg.com/vi/LL5geSy-U-I/mqdefault.jpg)

![[CVPR 2026] Dense Metric Depth Completion from Sparse Direct Time-of-Flight Sensors](https://i.ytimg.com/vi/_0dIKkF1Oko/mqdefault.jpg)
![[CVPR 2026] Agentic Retoucher for Text-to-Image Generation](https://i.ytimg.com/vi/6nGqMgUKjcQ/mqdefault.jpg)

![[CVPR 2026] Explicit Recovery Behavior for Diffusion Policies (REACH)](https://i.ytimg.com/vi/KplN4ncy3fU/mqdefault.jpg)
![CVPR 2026 | [HIGHLIGHT PAPER] Unsafe2Safe: Controllable Image Anonymization for Downstream Utility](https://i.ytimg.com/vi/-gbm4KDn63M/mqdefault.jpg)
![[CVPR 2026]](https://i.ytimg.com/vi/YYRFWBM9x-g/mqdefault.jpg)
![[CVPR 2026] Spatial-Frequency Aligned Diffusion Features for Cross-Sparsity Correspondence](https://i.ytimg.com/vi/AyU5uoErgRo/mqdefault.jpg)
![[CVPR 2026] Condensed Test-Time Adaptation of VLMs for Action Recognition](https://i.ytimg.com/vi/q5YE1dgFWfo/mqdefault.jpg)

