Media Summary: Slides: We covered most of transformer circuits, and will cover ... How can we use the language of causality to understand and edit the internal mechanisms of AI models? Atticus Geiger ... Take your personal data back with Incogni! Use code WELCHLABS at the link below and get 60% off an annual plan: ...
Mechanistic Interpretability Part 1 Ml - Detailed Analysis & Overview
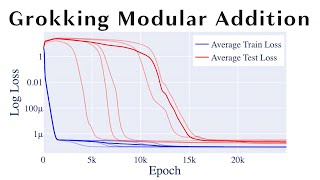
Slides: We covered most of transformer circuits, and will cover ... How can we use the language of causality to understand and edit the internal mechanisms of AI models? Atticus Geiger ... Take your personal data back with Incogni! Use code WELCHLABS at the link below and get 60% off an annual plan: ... The Cohere For AI community was honoured to welcome Catherine Olsson to discuss the process of getting started in A coding tutorial on how to reverse-engineer a model trained to grok modular addition! I'm joined by Jess Smith in this replication ... The model works. But WHICH neurons encode 3D contacts? Which attention head learned co-evolution? Open the clock and ...
In the first segment of the workshop, Professor Hima Lakkaraju motivates the need for This is a talk I gave to my MATS scholars, with a stylised history of the field of This is a talk I gave to my MATS 9.0 training scholars about the big picture of mech interp - as of Oct 2025, what had changed? Unpacking the multilayer perceptrons in a transformer, and how they may store facts Instead of sponsored ad reads, these lessons ...


![The Dark Matter of AI [Mechanistic Interpretability]](https://i.ytimg.com/vi/UGO_Ehywuxc/mqdefault.jpg)