Media Summary: In this video, I'll be deriving and coding Speaker: Charles Frye From the Modal team: Why does your GPU run out of memory when training or running large language models? In this episode of Bielik Anatomy, we ...
Triton Flash Attention From Scratch - Detailed Analysis & Overview
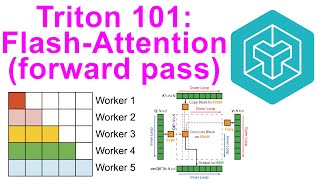
In this video, I'll be deriving and coding Speaker: Charles Frye From the Modal team: Why does your GPU run out of memory when training or running large language models? In this episode of Bielik Anatomy, we ... FlashAttention is an IO-aware algorithm for computing This detailed tutorial explains the motivation behind vanilla This video explains FlashAttention-1, FlashAttention-2, and FlashAttention-3 in a clear, visual, step-by-step way. We look at why ...
Episode 67 of the Stanford MLSys Seminar “Foundation Models Limited Series”! Speaker: Tri Dao Abstract: Transformers are slow ... In our quest to build a deep learning framework, we have hit a roadblock! Training is too slow and needs too much memory for ...