Media Summary: We discuss our new paper, "Natural emergent misalignment from In this AI Research Roundup episode, Alex discusses the paper: ' The AI Core in conversation with Richard Sutton, discussing RL agents and
C8 Rlhf Reward Hacking - Detailed Analysis & Overview
We discuss our new paper, "Natural emergent misalignment from In this AI Research Roundup episode, Alex discusses the paper: ' The AI Core in conversation with Richard Sutton, discussing RL agents and Sometimes AI can find ways to 'cheat' and get more How do you know that a language model is actually training on the right data and not just gaming the system? Catch these talks ... In this video, I dive into OpenAI's recent article 'Detecting Misbehaviour in Frontier Reasoning Models' and explore how powerful ...
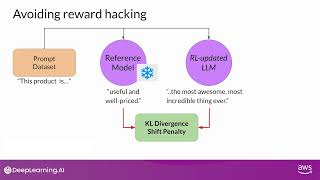
Strengthen your technical foundations with Brilliant! Visit to start learning for free and save 20% off ... Deep Reinforcement Learning lecture 8/8. In this lecture covers common failure modes for Deep Reinforcement Learning. [PoD] Reward Hacking in Rubric-based Reinforcement Learning Ever noticed AI sometimes agrees too easily, sounds overly confident, or tells you exactly what you want to hear? That may not be ...










![[PoD] Reward Hacking in Rubric-based Reinforcement Learning](https://i.ytimg.com/vi/nW238jvwIaY/mqdefault.jpg)

