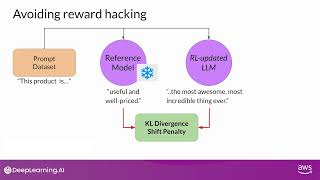
Media Summary: Sometimes AI can find ways to 'cheat' and get more Three different approaches that might help to prevent Goodhart's Law, Partially Observed Goals, and Wireheading: some more reasons for AI systems to find ways to 'cheat' and get ...
Reward Hacking Concrete Problems In - Detailed Analysis & Overview
Sometimes AI can find ways to 'cheat' and get more Three different approaches that might help to prevent Goodhart's Law, Partially Observed Goals, and Wireheading: some more reasons for AI systems to find ways to 'cheat' and get ... Cassidy Laidlaw's research proposes a new definition of We discuss our new paper, "Natural emergent misalignment from AI Safety isn't just Rob Miles' hobby horse, he shows us a published paper from some of the field's leading minds. More from Rob ...
In this AI Research Roundup episode, Alex discusses the paper: ' In this AI Research Roundup episode, Alex discusses the paper: 'GARDO: Reinforcing Diffusion Models without DeepSeek's GRPO (Group Relative Policy Optimization) Reinforcement Learning for LLMs. This video covers the shift from PPO ... For more information about Stanford's online Artificial Intelligence programs, visit: ... To learn, you need to try new things, but that can be risky. How do we make AI systems that can explore safely? Playlist of the ...



![Cassidy Laidlaw - A New Definition & Improved Mitigation for Reward Hacking [Alignment Workshop]](https://i.ytimg.com/vi/s_I-6AJfz58/mqdefault.jpg)